Accélération GPU dans COMSOL Multiphysics®
Les dernières versions de COMSOL Multiphysics® introduisent de nouvelles capacités pour accélérer les simulations en utilisant les processeurs graphiques (GPU) NVIDIA®. Ces améliorations élargissent le panel des modèles pouvant bénéficier des GPU; elles incluent des solveurs directs creux applicables à n'importe quelle application physique ou multiphysique ainsi que la prise en charge des simulations acoustiques explicites en temps et l'entraînement de modèles de substitution à réseau de neurones profond. En version 6.4, la prise en charge des GPU pour les solveurs directs est complètement intégrée à l'architecture solveur standard, ce qui permet aux utilisateurs et utilisatrices de bénéficier de l'accélération GPU pour des modèles existants sans avoir besoin de modifier des réglages physiques sous-jacents.
Accélération GPU pour des solveurs linéaires directs creux
L'une des étapes les plus consommatrices en temps dans un grand nombre de simulations par éléments finis est la résolution répétée de grands systèmes linéaires creux. Ce genre de système émane de la discrétisation implicite en temps, des itérations non linéaires, des analyses aux fréquences propres, et des balayages paramétriques. Pour ces types d'études, la version 6.4 de COMSOL Multiphysics® inclut désormais le solveur linéaire direct creux (cuDSS) de NVIDIA CUDA®. Ce solveur réalise des factorisations de matrices avec un ou plusieurs GPU sur une seule machine, ce qui permet de bénéficier d'une grande bande passante de mémoire et d'une parallélisation massive fournie par les systèmes GPU récents.
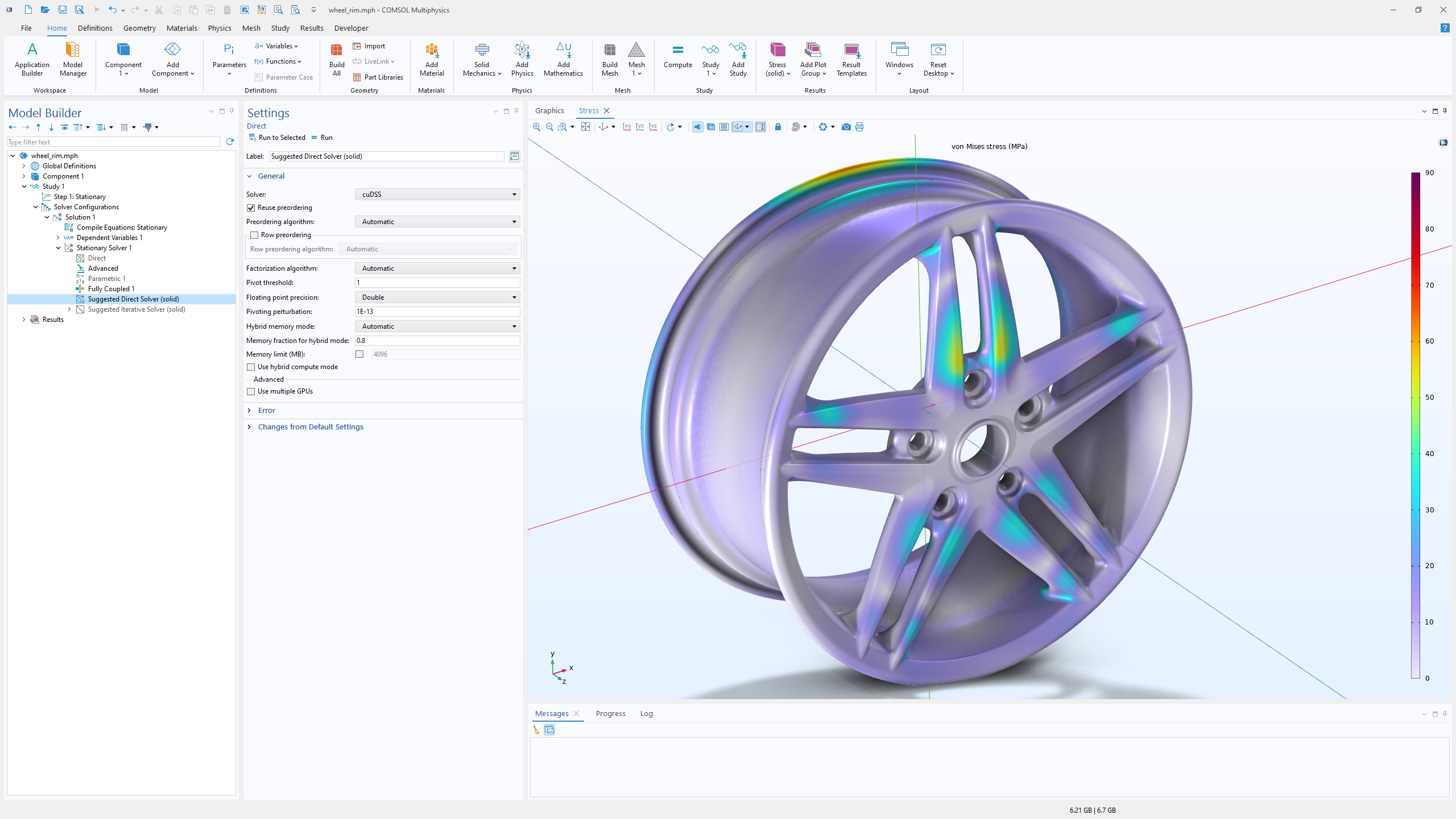
Les améliorations de performances varient selon les applications, mais des réductions significatives du temps de calcul ont été observées pour des modèles avec plusieurs millions de degrés de liberté (DDL). Par exemple, sur la simulation d'un benchmark d'acoustique thermovisqueuse impliquant une analyse multiphysique de la transmisssion acoustique à travers une plaque perforée, la résolution sur plusieurs GPU NVIDIA® H100 a conduit à des temps de calcul significativement plus courts comparé à un système double processeur CPU. Des modèles standards de mécanique du solide montrent également des améliorations franches lorsque l'on déporte la phase de solveur direct sur un GPU de station de travail comme la RTX 5000 Ada.
L'implémentation de cuDSS prend en charge l'arithmétique double-précision et simple-précision. Etant donné que la simple précision réduit l'utilisation de mémoire de moitié, elle peut améliorer les performances sur n'importe quelle carte sur laquelle l'application atteint les limites de mémoire, y compris sur des GPU moins coûteux. Le fait qu'un modèle soit ou non adapté à la simple précision dépend de son conditionnement numérique, ce qui est influencé par la qualité du maillage, les paramètres matériau, et les physiques sous-jacentes. Utilisatrices et utilisateurs peuvent tester les modes de précision directement dans les réglages solveur et sélectionner le mode qui fournit des résultats stables avec la performance désirée.
Pression acoustique explicite en temps accélérée par GPU
La prise en charge des GPU NVIDIA® est également disponible pour les simulations acoustiques explicites en temps. Dans ce type de simulation, il est possible d'éviter la résolution de grands systèmes linéaires à chaque étape temporelle en faisant appel à des méthodes explicites en temps qui, à la place, utilisent des opérations vectorielles répétées et la mise à jour locale des éléments. Ces opérations sont fortement parallélisables et se prêtent efficacement au calcul GPU.
Cette capacité est particulièrement pertinente pour des simulations acoustiques à large bande et des domaines 3D, dans lesquels une résolution spatiale fine conduit à un grand nombre de pas de résolution temporels. Par exemple, les modèles d'acoustique de salle, tels que des open spaces de bureaux ou des salles de concert, peuvent requérir des dizaines de milliers de pas de temps pour résoudre précisément la propagation de l'onde. Déporter ces opérations sur des GPU peut significativement raccourcir le temps de simulation global.
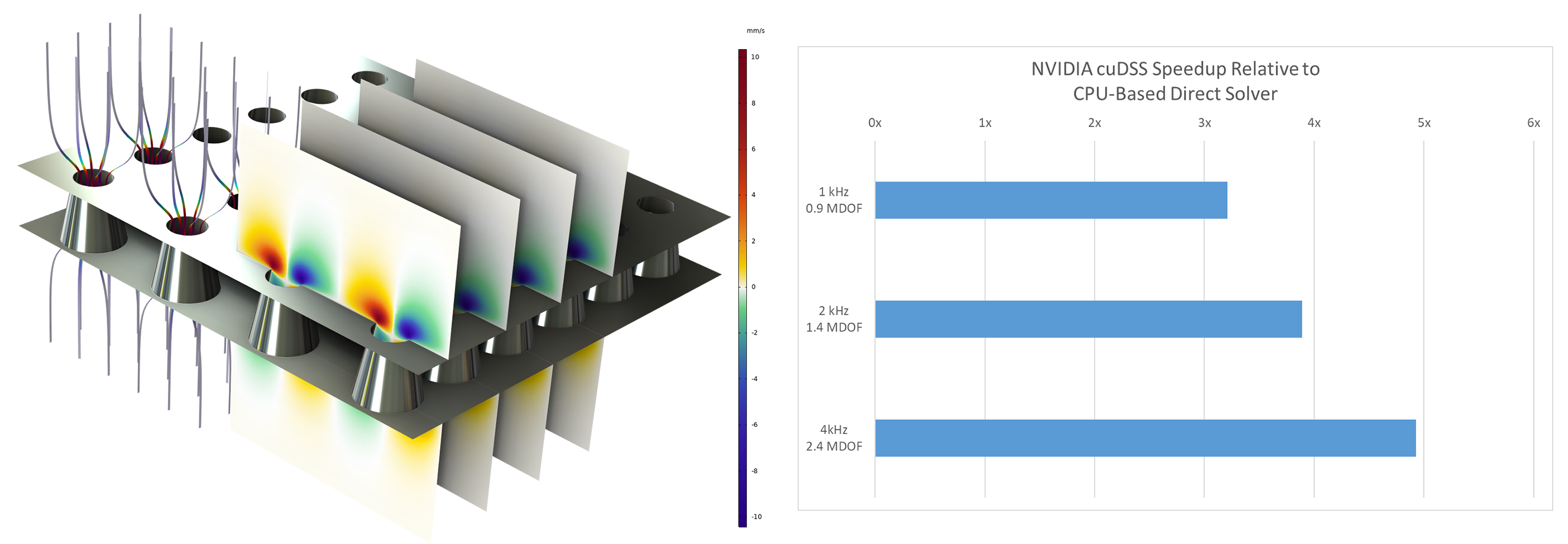
La formulation GPU pour l'acoustique explicite en temps prend en charge à la fois les systèmes mono GPU (introduite en version 6.3) et multi GPU (introduite en version 6.4), que ce soit sur un seul ordinateur ou bien sur les noeuds d'un cluster. Cela rend possible la simulation de domaines comprenant des centaines de millions de DDL. Par exemple, dans un modèle ondulatoire de salle de concert, une simulation faisant intervenir près de 300 millions de DDL a été résolue en seulement quelques heures sur un seul GPU de classe data-center NVIDIA® H100, contre plusieurs heures sur plusieurs noeuds CPU. Des réductions similaires de temps de calcul ont été observées sur des simulations d'acoustique automobile et d'autres analyses transitoires à grande échelle.
Note: l'interface Pression acoustique, explicite en temps est prise en charge pour tous les types de licences lorsque l'on utilise un seul GPU, mais nécessite une licence réseau (FNL) lorsqu'on utilise plusieurs GPU.
Propagation d'une impulsion initiale (centrée à 500 Hz) dans un modèle de salle de concert de musique de chambre avec 300 millions de DDL, résolu sur un GPU NVIDIA® H100 de classe data-center.
Prise en charge GPU pour l'entraînement de modèles de substitution
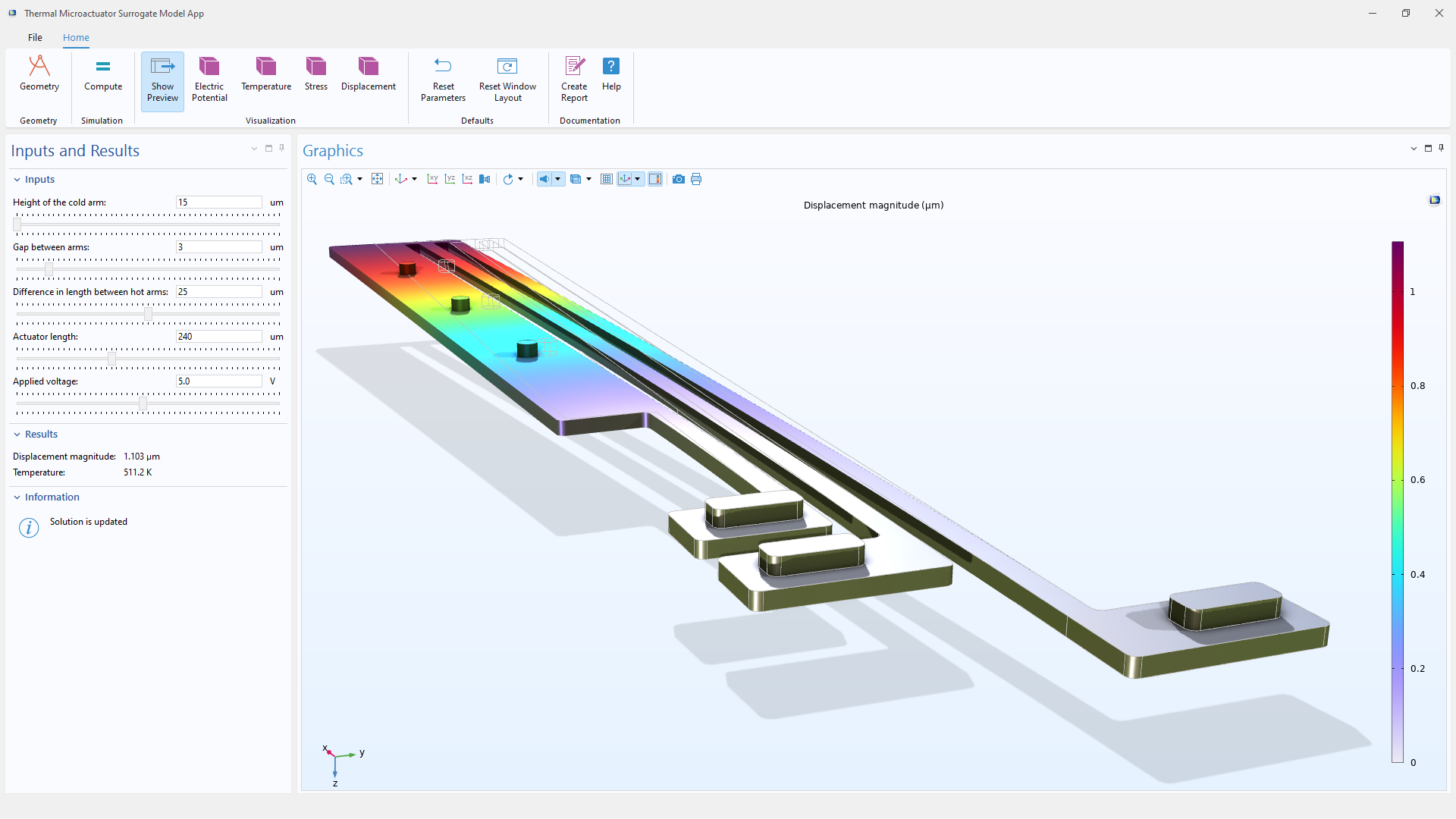
Depuis la version 6.3, COMSOL Multiphysics® fournit également des outils pour générer des modèles de substitution DNN approximant des simulations numériques de haute fidélité. Entraîner ces réseaux requiert l'évaluation répétée de grands jeux de données et beaucoup de cycles d'optimisation, ce qui est particulièrement adapté pour l'accélération GPU. En réalisant la phase d'entraînement sur des GPU NVIDIA®, utilisateurs et utilisatrices peuvent réduire le temps requis pour l'exploration des architectures du réseau ou pour ajuster des hyperparamètres.
Des réseaux plus grands, qui pourraient être requis pour capturer des comportements multiphysiques complexes ou de la reconstruction spatiale de modèles, peuvent également bénéficier de l'augmentation de la bande passante de mémoire et des capacités de calcul parallèle dees GPU. La prise en charge des GPU pour l'entraînement des DNN est disponible directement dans l'interface Modèle de substitution et fonctionne sans produit additionnel.
Pour aller plus loin
Pour en apprendre davantage sur l'accélération GPU dans COMSOL Multiphysics®, vous pouvez consulter:
- Points forts de COMSOL Multiphysics® 6.4: Nouveautés pour les études et les solveurs
- Points forts de COMSOL Multiphysics® 6.4: Nouveautés du module Acoustics
- Configuration requise: COMSOL Multiphysics® Version 6.4
- Setting Up GPU-Accelerated Computing Within COMSOL Multiphysics®
NVIDIA, CUDA, and RTX are trademarks and/or registered trademarks of NVIDIA Corporation in the U.S. and/or other countries. Intel and Xeon are trademarks of Intel Corporation in the U.S. and/or other countries.